Chapter 5 of 8
Extraction
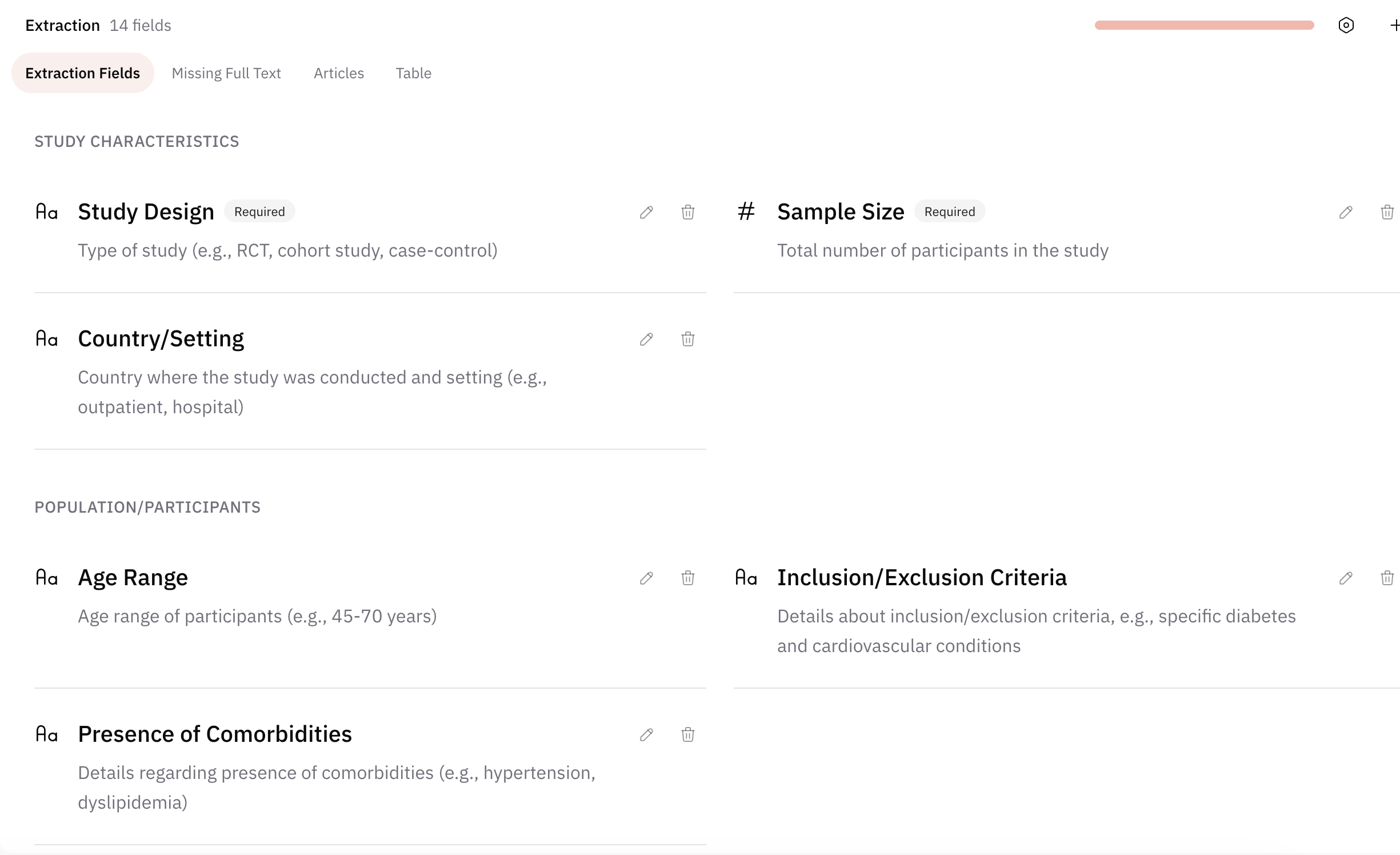
After screening, the workflow moves to full-text data extraction. The planning step is to define extraction fields—the structured items you will capture from each included study (for example population, intervention, outcomes, effect sizes, risk-of-bias items, or any data your synthesis needs).
AIPRA helps teams decide which fields matter most by starting from your research question and asking a short set of targeted questions. Those answers steer the field list toward what will actually feed your analysis and reporting.
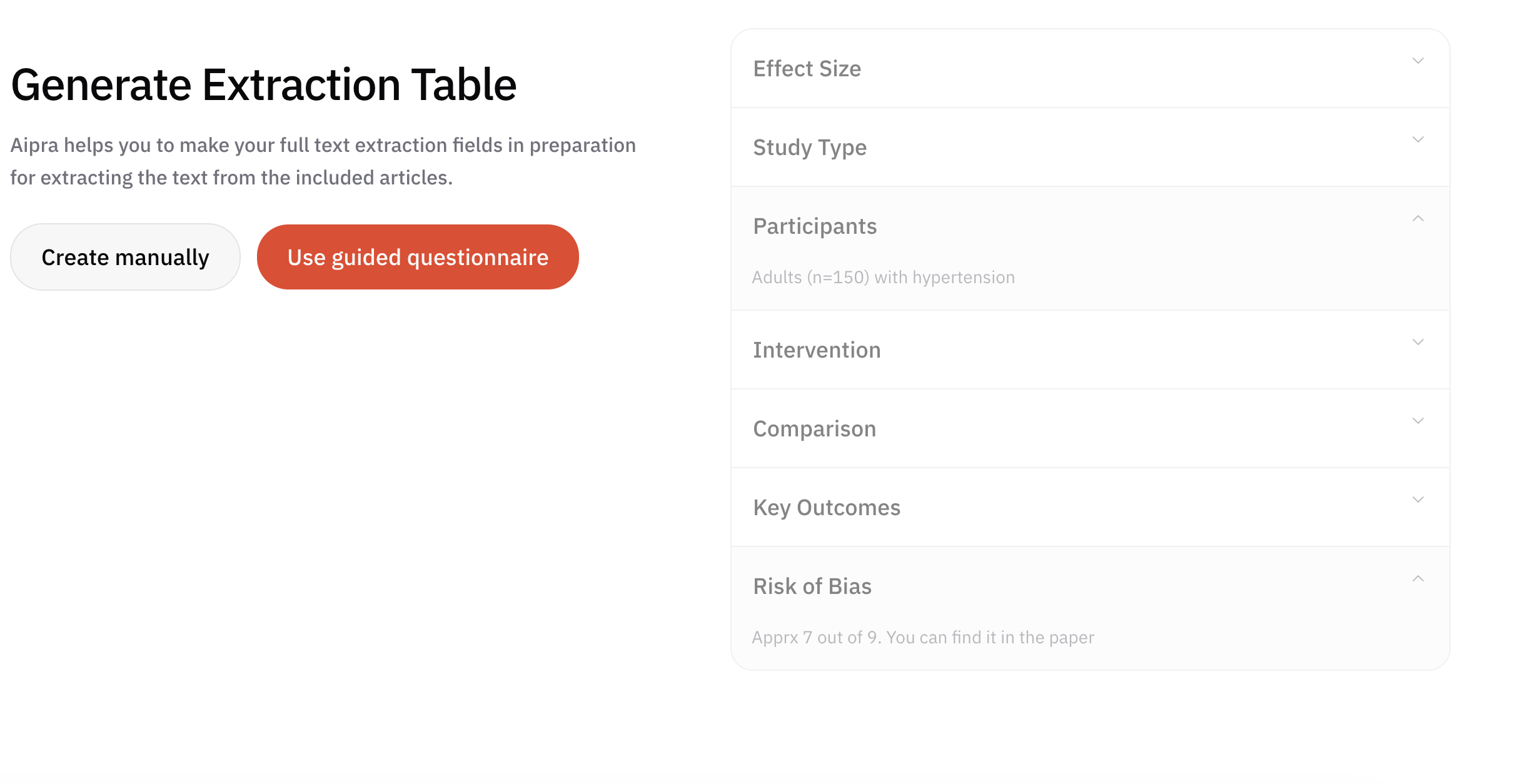
Well-chosen fields define what your results section can support: they are the backbone of the evidence tables, figures, and narrative synthesis readers will see later.
Running extraction from full text
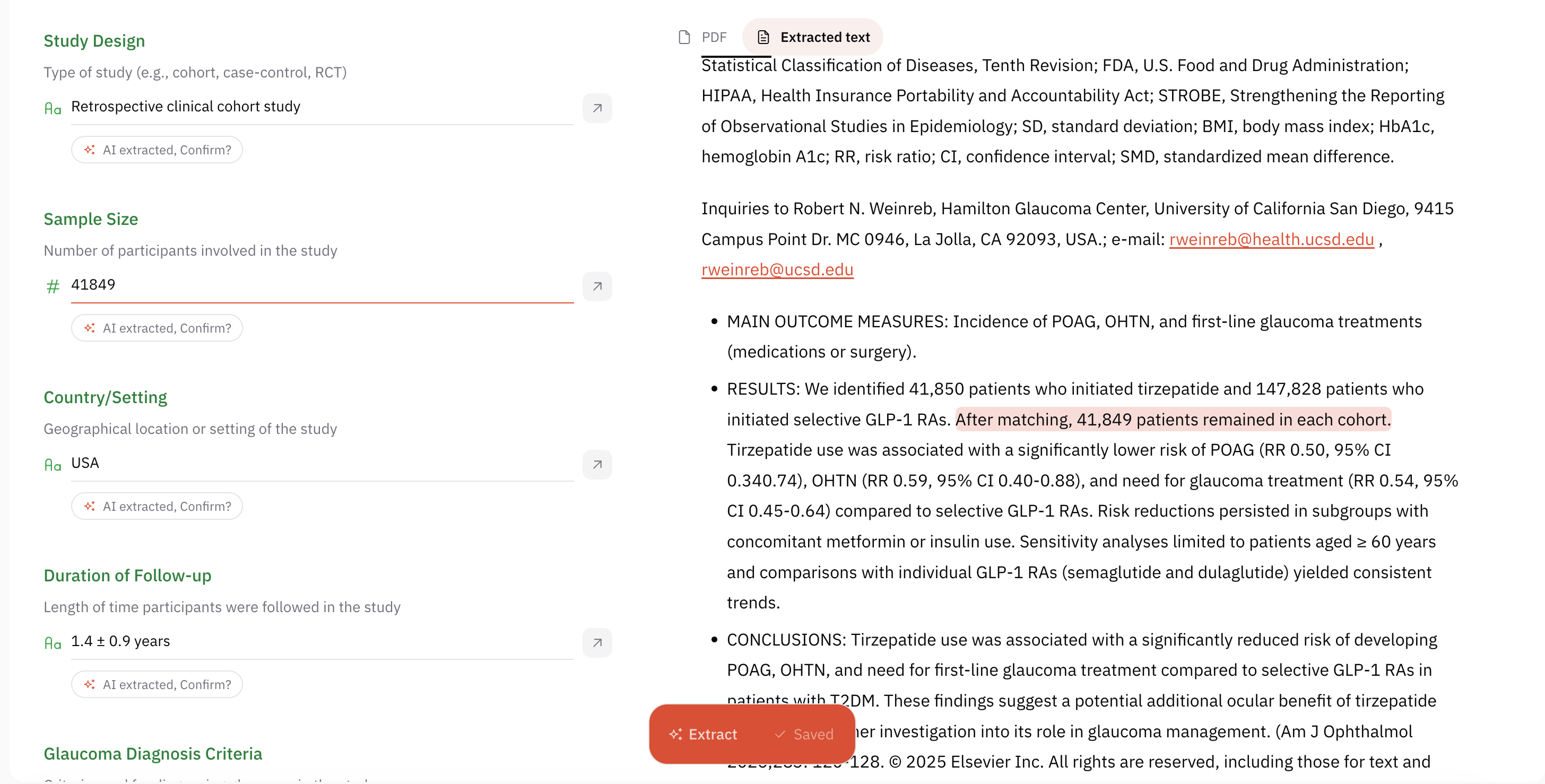
Once fields are fixed in the protocol, reviewers extract values from each study’s full text into those fields. For quality and accuracy, many teams use two independent reviewers per study (or per field), with a process to compare entries and resolve discrepancies—similar in spirit to dual screening.
AIPRA-assisted extraction
AIPRA can accelerate extraction by proposing values for many fields directly from the full text. Where it fills a field, it can attach an exact quotation or pointer to the passage the value came from so reviewers can verify quickly and keep the audit trail clear.
Human review remains essential: you should treat machine-filled entries as drafts to confirm against the source, especially for outcomes, numbers, and nuanced design features.